Pond: CXL-Based Memory Pooling Systems for Cloud Platforms
Introduction
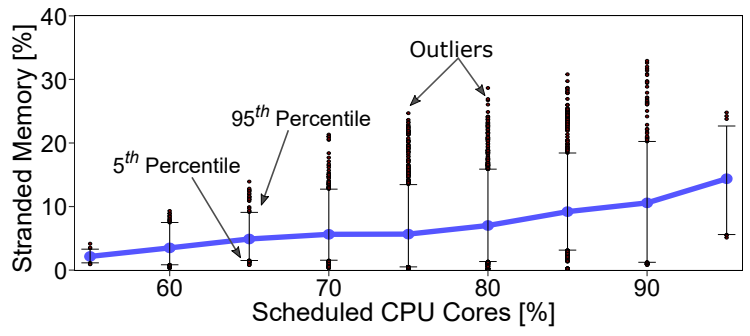
Public cloud providers are constantly balancing the need for top-tier virtual machine (VM) performance with the harsh reality of hardware costs. Main memory (DRAM) accounts for a staggering 50% of the total server cost in modern datacenters. A major culprit behind this expense is "memory stranding." This phenomenon occurs when all CPU cores on a server are rented out to customers, leaving the remaining unallocated memory completely unusable by other systems.
- At the 75th percentile, 6% of memory is stranded
- At the 85th percentile, 10% of memory is stranded
- At the 95th percentile of server utilization, up to 25% of memory can become stranded.
Additionally, due to overprovisioning by customers, nearly half of all rented VM memory goes untouched. While memory pooling via the Compute Express Link (CXL) standard allows load/store access without the heavy page-fault overheads of RDMA, it adds roughly 70-90ns of latency essentially doubling the access time compared to local DRAM. Because 60% of cloud workloads experience more than a 5% slowdown under CXL latencies, naive pooling is impossible. Pond is designed to pool this stranded and untouched memory intelligently, maintaining strict cloud performance standards.
Architecture
Pond utilizes a hardware-software co-design to achieve its goals.
Hardware Layer
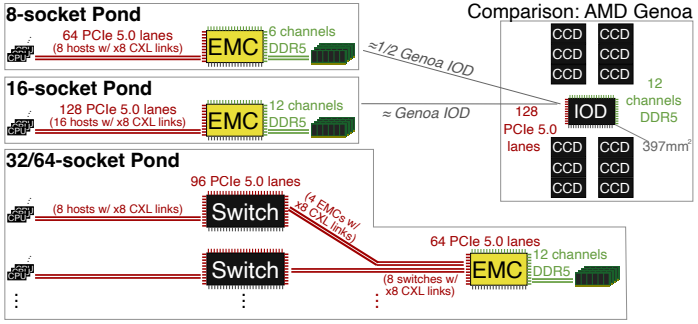
Pond introduces a multi-headed External Memory Controller (EMC) ASIC that allows multiple CPU sockets (typically 8 to 16) to access a shared pool of DDR5 memory via the CXL.mem protocol. When implementing CXL Type 3 memory expansion controllers on FPGAs or ASICs, managing latency overhead is a massive challenge. Pond tackles this by avoiding complex switches entirely, connecting the multi-headed EMC directly to standard server blades to keep latencies within acceptable bounds.
System Software
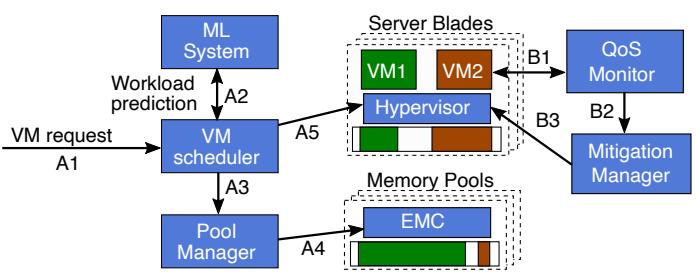
Pond exposes the pooled memory to the VM's guest operating system as a "zNUMA" (Zero-Core NUMA) node. Modern operating systems are designed to preferentially allocate memory to local NUMA nodes where active cores reside. By creating a NUMA node with memory but zero cores, Pond tricks the guest OS into treating the CXL pool as a last resort, ensuring that only the "untouched" portion of a VM's memory footprint ever spills into the slower pool.
Control Plane
Pond uses a machine learning (ML) system interconnected with the VM scheduler. The ML models predict whether a workload is latency-insensitive (allowing it to run entirely on pool memory) and predict the amount of "untouched" memory a standard VM will have. If poor performance is ever observed, a Quality of Service (QoS) monitor works with a mitigation manager to migrate resources back to local memory.
Methodology
The researchers evaluated Pond using a mix of lab experiments and large-scale simulations. They tested 158 different workloads. Including proprietary cloud workloads, Redis, Spark, GAPBS, TPC-H, and SPEC CPU 2017, under emulated CXL latencies of 182% and 222% relative to local DRAM. To evaluate end-to-end memory savings, they fed their simulator with production VM traces collected from 100 Azure clusters over a 75-day period.
Results
Pond's evaluation yielded several compelling findings.
Cost Savings
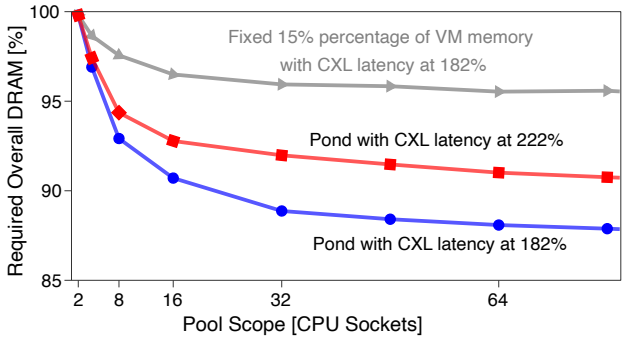
By pooling memory across 8-16 sockets, Pond achieved a 7-9% reduction in overall DRAM requirements, which translates to a massive 3.5% reduction in total cloud hardware costs. Larger pool sizes provided diminishing returns and incurred higher latency penalties. In contrast, scaling up to 64 sockets yeilded 13% savings but doing so required CXL switches that pushed access latencies beyond 270ns.
Performance
The ML prediction model achieves 7-9% saving by pooling by successfully identifying 25% of untouched memory across the fleet while only overpredicting for 4% of VMs.
zNUMA Effectiveness
The zNUMA abstraction worked exceptionally well. Workloads correctly predicted to have untouched memory sent less than 0.38% of their memory traffic to the slower CXL pool, virtually eliminating any latency penalties.
Discussion
While Pond offers a robust solution for standard cloud workloads, there are a few practical considerations to keep in mind.
QoS Mitigation Overhead
When the ML model mispredicts and a VM heavily accesses the slower zNUMA node, Pond relies on a mitigation process. This requires temporarily turning off virtualization accelerators to perform memory copy operations. If a workload frequently requires reevaluation, this copying process could become a severe performance bottleneck.
Applicability to AI
Modern AI workloads are fiercely latency-sensitive and require massive amounts of memory. Because their memory access patterns rarely leave large chunks of memory "untouched," Pond's current pooling approach is likely unsuitable for AI clusters.
Fragmentation Issues
Software allocators (like user-space malloc) tend to fragment memory, grabbing more pages than strictly needed. While Pond effectively tackles "stranded" memory at the hypervisor level, managing highly fragmented "unused" memory within the VM remains a stubborn software challenge.
Conclusion
Pond represents a major step forward in cloud infrastructure, demonstrating that CXL-based memory pooling is both viable and economically impactful. By intelligently combining a multi-headed hardware controller with a software-defined zNUMA abstraction and machine learning telemetry, Pond successfully reclaims stranded memory. It achieves near-local DRAM performance while significantly driving down the hardware costs that plague modern datacenters, making it an essential blueprint for the future of cloud scaling.
AI Disclosure
- Gemini to help summarize paper and scribe notes.