How modern AI workloads are bottlenecked by GPU hardware
Introduction
Transformer models have become the dominant architecture in modern natural language processing systems. As model sizes increase and inference workloads scale, understanding how efficiently hardware is utilized becomes increasingly important. Many transformer workloads are executed on GPUs because of their high compute throughput and large memory bandwidth. However, GPUs still face performance bottlenecks when executing transformer workloads. In particular, inference performance can be limited by either compute throughput or memory bandwidth depending on the workload configuration.
Objective
In this project, we analyze the hardware bottlenecks of transformer inference by benchmarking GPT-2 models under varying input conditions.
We measure latency and throughput while systematically varying sequence length and batch size.
Using these measurements, we evaluate how GPU resources are utilized and identify whether the workload becomes compute-bound or memory-bound.
For this project, we evaluated the following models:
- GPT-2 Small (124M parameters)
- GPT-2 Medium (355M parameters)
The larger GPT-2 Medium model contains nearly three times as many parameters as GPT-2 Small and performs significantly more computation per token. Comparing these two models allows us to examine how increasing model size affects hardware utilization.
Methodology
For the project, we made use of two tools known as Pytorch and Transformers. Both are python based open-source tools that allow for machine learning and research. With these tools, we created a benchmarking script that recorded several metrics. The script can be found in a repo linked at the bottom.
How the script works
To put it simply, for each configuration:
- The model was loaded into memory.
- Synthetic text input was tokenized.
- Batched inference runs were executed.
- Runtime performance metrics were recorded.
We varied parameters like:
- Sequence Length (16, 32, 64,128, 256 tokens)
- Batch Size (1, 2, 4, 8)
Each configuration was executed multiple times and the average runtime was recorded.
Two metrics were used to evaluate performance:
- Latency (Average inference time per run).
- Throughput (Tokens processed per second). This was calculated in the script as Batch Size times Sequence Length, divided by latency.
Evaluation
As seen in below, the benchmark results show that throughput generally increases with batch size and sequence length until it begins to plateau. For GPT-2 Small, throughput increases rapidly as batch size grows, eventually stabilizing around 700–800 tokens per second. This suggests that the hardware reaches a utilization limit where additional parallelism no longer improves performance. GPT-2 Medium shows a similar pattern but achieves significantly lower throughput due to its larger parameter count and higher computational cost.
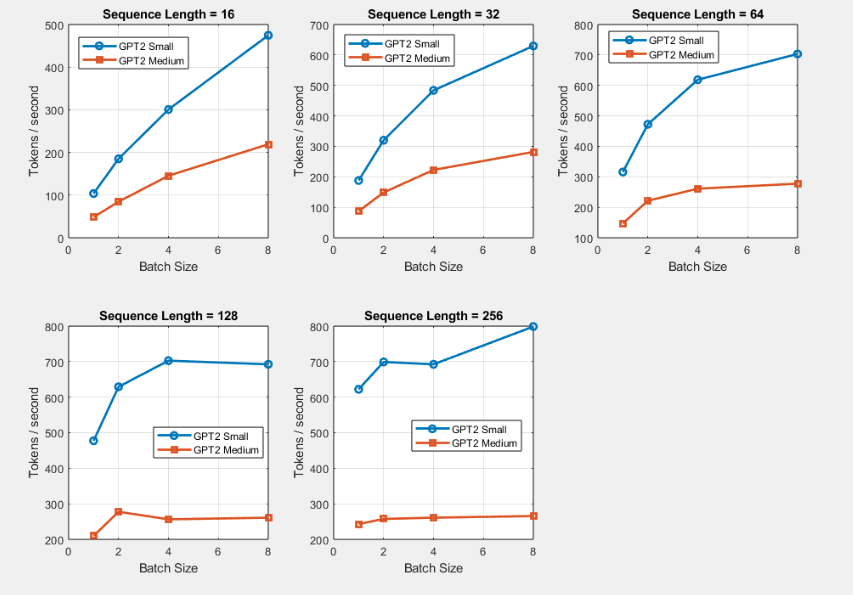
Increasing batch size significantly improves throughput at small batch sizes.
Performance gains saturate at larger batch sizes.
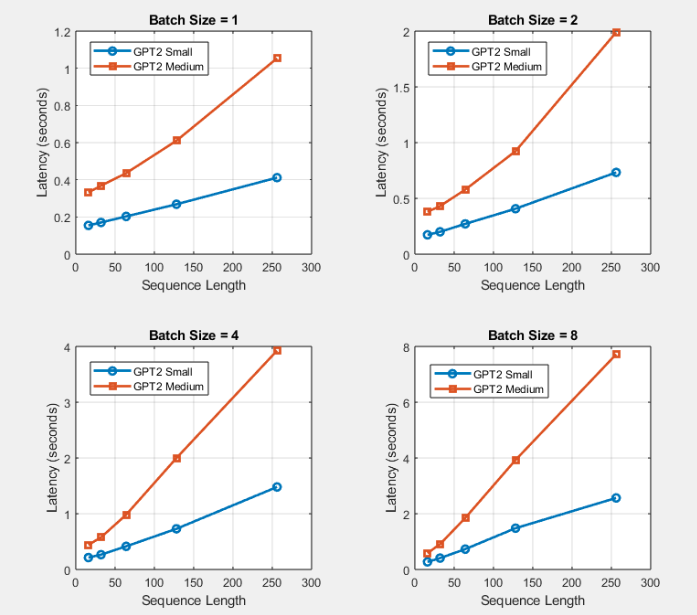
We can see here that latency increases as sequence length grows across all batch sizes
Conclusion
The observed throughput saturation shows that memory bandwidth, rather than compute capacity, limits inference performance under many configurations. This explains why throughput improvements diminish at larger batch sizes even though additional parallel work is available.
Were we successful?
Although we were able to identify that the workload was primarily memory-bound, our evidence and data is somewhat lacking. There is much more that could be done to further reinforce our conclusion.
Challenges and future possibilities
This experiment utilized AMD Radeon TM Graphics, which is an integrated GPU. Future experiments can be done on higher-end GPUs that make will have higher bottlenecks of performance. These higher-end GPUs can also make use of tools like ROCm and NVIDIA Nsight to collect data on kernel execution time and GPU utilization. With GPU hardware counters, we could also use a roofline-style analysis that would provide further insight into the AI performance.
Repo
The scripts used to generate the data collected in this project can be found at https://github.com/IMPULS3D/AI-Hardware-Bottleneck-scripts. Some early results of the experiments can also be found in the repo.
Division of responsibilities
- Darren: Created slides and presented. Wrote and coded the script as described in the blog. Collected the data.
- Dustin: Created slides and presented. Organized data and wrote a script.
AI Disclosure
ChatGPT was used to aid in formatting blog.