FPGA Backed Far Memory with Hardware Managed Tiering and In Tier COPY/ZERO
Introduction
In modern memory, there are many data-intensive workloads, from large-scale systems that focus on recommendations and graphs for analytics to in-memory key-value stores, which are increasingly constrained by the total cost and the physical limitations of DRAM. As the dataset sizes increase faster than the per-server memory capacity, the systems hit what is essentially a memory wall. Where it becomes too expensive in terms of both hardware cost and power consumption. With many workloads of applications that may require working sets that exceed the limits of a single node in local memory.
Far memory is one of the ideas that could be a promising solution to this problem. The main idea is to extend a system’s effective memory capacity by treating another secondary system with higher latency memory resources as another tier of memory in the system. This type of system has been explored before with RDMA-connected nodes, CDL-attached devices, and other networked disaggregated memory pools. These approaches typically require a lot of specialized hardware and even specialized datacenters, all of which are not that broadly accessible for research.
In our approach, we explored a different concept of far-memory usage: using the DDR3 memory attached to a commodity FPGA development board as a remote backing store, accessible from a host CPU over a USB 3.0 port. This approach leverages the Opal Kelly XEM7320 FPGA module and the Xilinx MIG DDR3 controller to provide a physically separate, software-managed memory tier. While on the host side, we built a user-space paging runtime - farmem - that intercepts memory accesses via Linux’s userfaultfd system and moves pages between local DRAM and the FPGA’s DDR3 memory.
This system was put through an evaluation that covered four workloads that represent different memory access patterns: Redis with memtier, Memcached with memtier, TorchRec fused embeddings, and GAPBS BFS. The results that were achieved show that under workloads with sufficient locality, with a skewed key value access and optimized embedding lookups, far memory can substantially reduce managed DRAM residency while maintaining an acceptable throughput and tail latency. Irregular workloads such as graph traversal reveal a sharp capacity threshold.
Specifications
This project implemented both hardware and software components in both the implementation and evaluation phases of the FPGA-backed tiered memory system. The hardware provides the physical platform for the memory storage and acceleration logic, while the software allows development, control, and benchmarking of the system.
Hardware
The hardware setup consists of a host computer and an FPGA development board.
- FPGA (XEM7320-A75T)
The FPGA acts as the far-memory tier in the system. It stores memory pages that are not currently needed in host dram and executes near-memory operations such as page copying and zeroing directly inside the FPGA memory. The FPGA also implements metadata tracking logic that monitors page accesses and helps identify cold pages for eviction.
- Laptop/Host computer
The laptop runs the operating system and hosts the applications that use the tiered memory system. It also runs the paging manager software that communicates with the FPGA and handles memory faults via Linux mechanisms.
Software
Several software tools and applications are used for development, communication with the FPGA, and performance evaluation.
- Opal Kelly SDK
The Opal Kelly SDK is a software library and driver package that lets a host program communicate with an Opal Kelly FPGA board ( XEM7320) over USB. It provides: USB drivers, host-side APIs (C/C++/Python/etc), communication primitives to send data and control signals to the FPGA.
- Vivado
Vivado is used to design, synthesize, and program the FPGA hardware modules that implement the page store, command interface, and metadata tracking logic.
- Redis Benchmarking Application
Redis is used as a memory-intensive workload to evaluate the performance of the tiered memory system under realistic conditions.
- Memcached
Memcached provides an additional in-memory workload useful for testing memory behavior and caching patterns.
- GAPBS (Graph Benchmark Suite)
GAPBS workloads allow the system to be tested using graph processing tasks that stress memory access patterns.
- TorchRec
TorchRec workloads simulate recommendation system tasks that involve large datasets and memory-intensive operations, providing another benchmark scenario for evaluating the tiered memory system.
Design and Implementation
Host System Overview
On the host side, the system functions as a software paging controller for a user-space memory arena. The host runtime is responsible for managing page allocation, handling page faults, and coordinating the movement of pages between DRAM and FPGA memory.
The host performs three main functions:
- Determine which allocations should be placed in farmem-managed memory.
- Serve page faults when those pages are touched.
- Evict resident pages back to FPGA DDR when local DRAM exceeds a threshold.
In this architecture, the host is the brain/control plane, while the FPGA DDR is the remote backing store.
The host runtime contains several components:
- Allocation logic
- Page-state tracking
- Userfaultfd page-fault handler
- Eviction policy
- FrontPanel communication with the FPGA
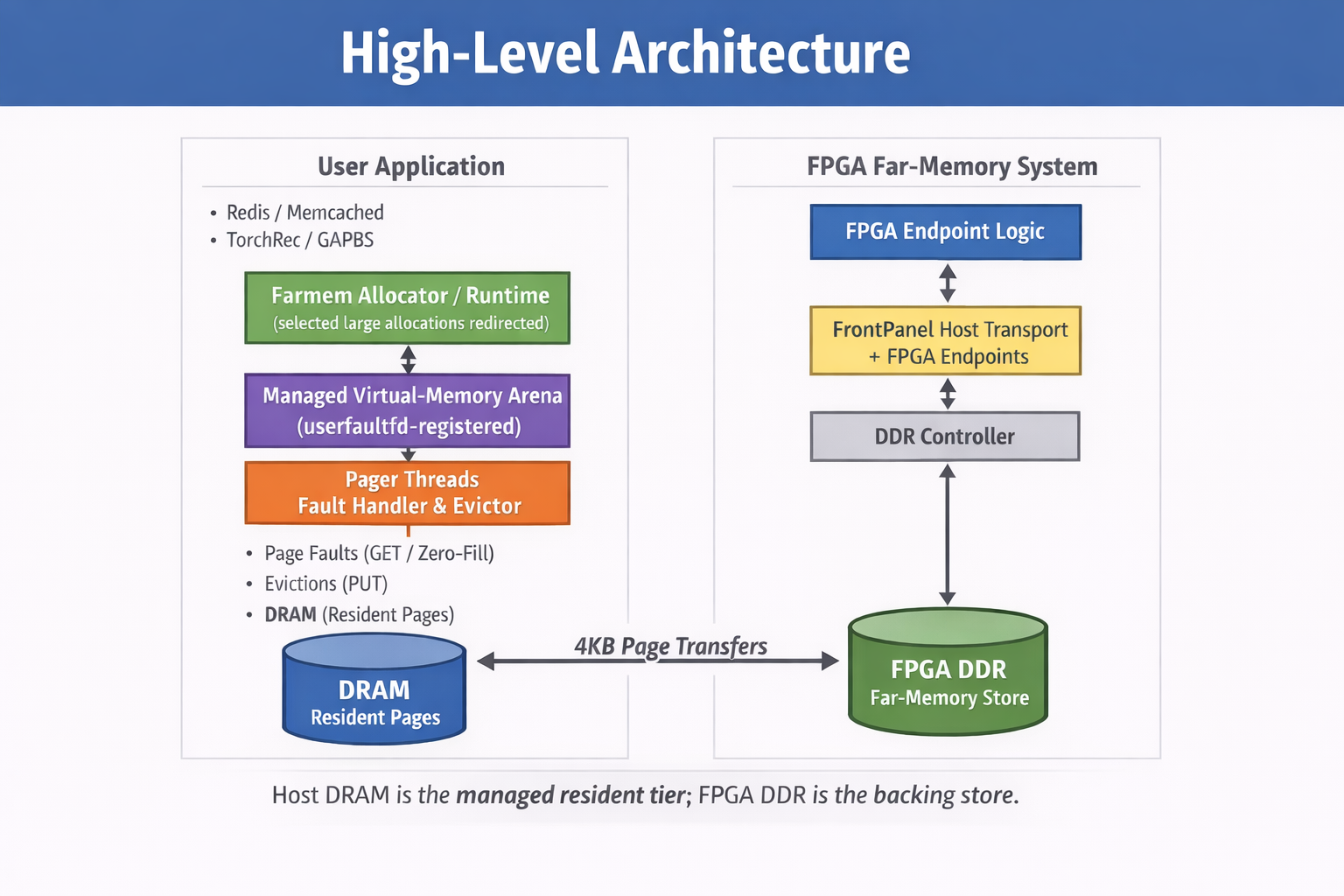
Allocation Stage
When the application calls farmem_malloc or farmem_calloc, the host runtime first determines whether the allocation should be handled by the farmem system.
The allocation is routed into the managed memory arena if the following conditions are met:
- Farmem is enabled
- The allocation size exceeds the configured threshold
- The farmem handler has not encountered a failure
If any of these conditions are not met, the allocation falls back to standard libc memory allocation. This logic is implemented directly in farmem_malloc and farmem_calloc.
Once memory is placed inside the managed arena, it becomes part of the farmem paging system. When the application touches a page in this arena that is not currently resident in DRAM, the kernel does not just fill it automatically. Instead, it generates a page-fault event and forwards it to the host’s user-space pager thread for handling.
userfaultfd Registration
To intercept and manage page faults in the farmem memory arena, the host runtime sets up a userfaultfd interface.
The host creates a userfaultfd file descriptor, negotiates the API with the kernel, and registers the arena with it. In the pager code, this happens with:
- create_uffd() - creates the userfaultfd file descriptor
- UFFDIO_API - negotiates the userfaultftd API with the kernel
- UFFDIO_REGISTER - registers the managed memory region
The arena is registered in missing page mode, which allows the user-space pager to handle page faults when a page is accessed but not currently resident in memory. When supported by the system, write-protect mode is also enabled to allow the runtime to track page modifications.
Fault handling
The host’s fault handler thread sits in a loop polling and reading events from userfaultfd. In fault_handler_loop, it:
- polls on the uffd,
- reads a uffd_msg,
- checks that the event is UFFD_EVENT_PAGEFAULT,
- rounds the address down to the page boundary,
- computes the page ID from the arena offset,
- and determines whether it is a write-protect fault or a normal missing page fault.
Why do we round down on a page fault?
- A page fault reports a byte address where the CPU tried to access memory. The kernel and user space pager must operate on whole pages, not single bytes.
- Rounding down maps the faulting byte address to the start address of the page that contains it, so the pager can load or initialize that entire page.
Host Page-State Logic
The host keeps page metadata for each page in the managed memory arena. This metadata tracks the current state of a page and helps the system decide how to resolve page faults.
The host keeps page metadata such as whether a page is:
- Absent - the page has never been backed remotely
- already in FPGA - the page exists in FPGA memory but is not currently resident in DRAM
- Resident - the page is currently present in host DRAM
- Loading - another handler thread is already fetching this page
Conceptually the decision is:
- ABSENT -> this page has never been backed remotely, so create it locally as zero
- IN_FPGA -> fetch its 4 KB contents from the FPGA
- RESIDENT -> it is already present locally
- LOADING -> another handler is already bringing it in
That is how the host knows whether to zero-fill or GET.
If the Page Exists Remotely: How the Host Retrieves It
If the faulted page is already in FPGA storage, the host fetches the 4 KB page over the transport path:
- Receive the 4 KB page bytes into a host buffer
- Install that page into the faulting virtual address
If the page has no prior remote contents, the host does not fetch from the FPGA. It resolves the fault with a zero page instead using UFFDIO_ZEROPAGE.
Installing the page: how the host actually resolves the fault
Once the host has either:
- a 4 KB buffer from FPGA
- a zero-fill decision It resolves the fault with userfaultfd ioctls.
Dirty Tracking
For fetched pages, it uses UFFDIO_COPY. For new zero-filled pages, it uses UFFDIO_ZEROPAGE.
That is the moment when the host turns a page-fault event into a valid resident page in local DRAM. After this, execution resumes.
Host runtime also supports write-protect-based dirty tracking.
In the fault handler, write-protect faults are detected through UFFD_PAGEFAULT_FLAG_WP.
This means the host can distinguish:
- a page that is merely resident
- from a page that has been written and is now dirty
That matters because, for background eviction, the host doesn’t choose dirty resident pages as victims in the current policy.
Resident Tracking
After a page becomes resident, the host pushes it into a FIFO-style resident queue and increments the resident count. The host tracks (how many pages are currently resident in local DRAM, and which ones are the oldest candidates for eviction)
- fifo_ids
- fifo_head
- fifo_tail
- resident_count
- resident_cap_pages
- resident_reserve_pages
- resident_high_watermark
Note - fault handling and eviction are separated, and eviction happens in a background evictor thread. So this is where the fault thread passes to the evictor.
High-watermark Policy
The host does not simply wait until DRAM is completely full. It uses a cap and reserve structure.
The host, as mentioned before, keeps track of: resident_cap_pages, reserve_pages, and high_watermark.
So the host policy is: keep the resident set below a high watermark, not just barely under the hard cap.
Eviction
When resident memory gets too high, the host’s evictor selects a victim page from the FIFO queue.
Then, before discarding the local copy:
- If the page is dirty or has not yet been backed up remotely, the host sends a PUT to the FPGA
- After that, it drops the local copy
- The page state becomes remote-backed rather than resident
reserve_pages is just several pages to keep as headroom
high_watermark = cap - reserve
When resident pages reach high_watermark, the evictor starts removing pages from far memory.
Refault
Later, if the application touches that evicted page again, the same page-fault loop runs again. Since the page state now says it is in FPGA, the host performs a GET instead of a zero fill. Optional prefetch is also there (default is 4), but we have kept it disabled, as the results were getting slightly worse with prefetch on.
Hardware Side Workflow
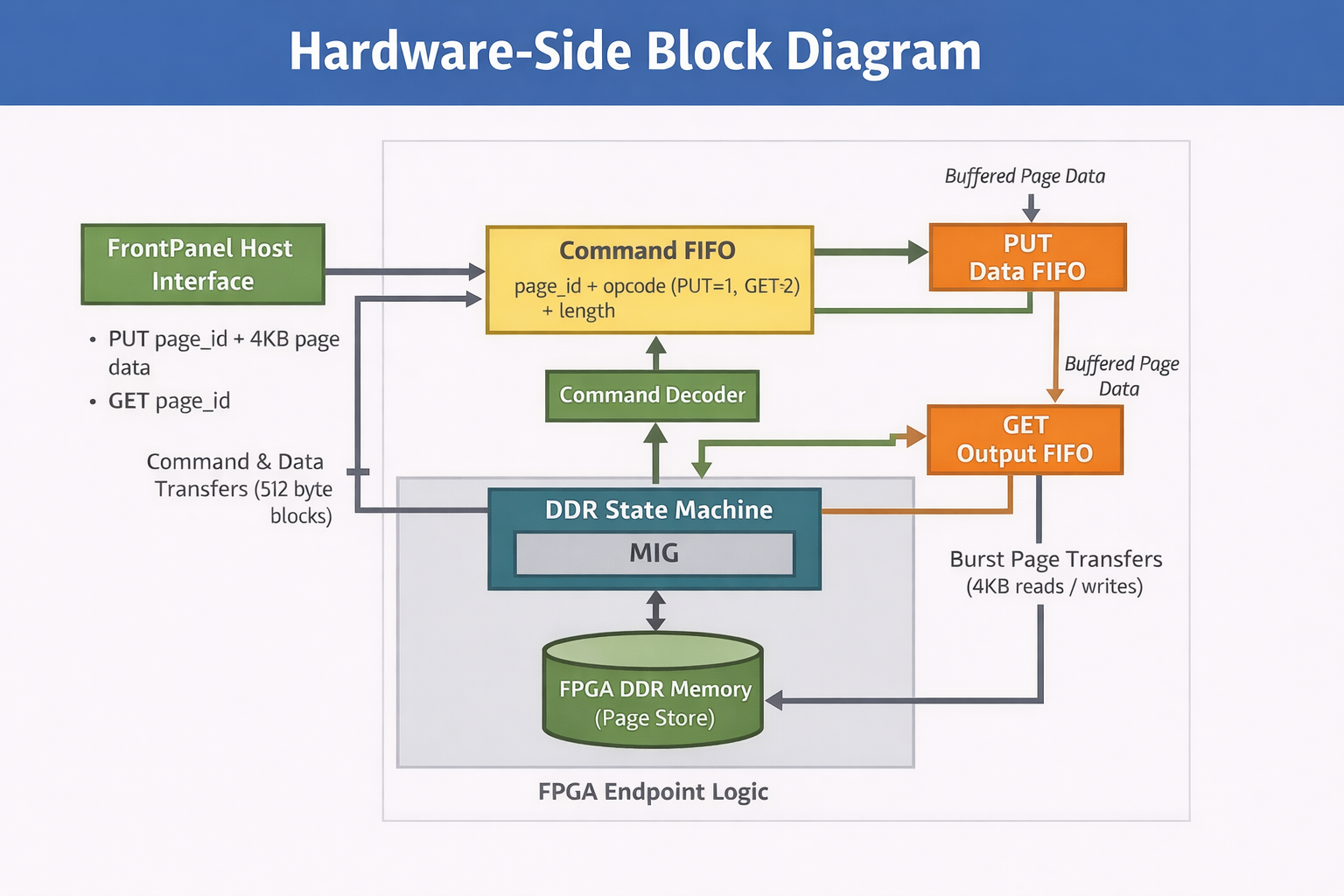
Host sends a command with: page_id opcode (PUT=1, GET=2) len_blocks (for 4KB page, this is 8 blocks of 512B) go pulse (0 -> 1 -> 0).
Endpoint config PUT wires: 0x01 (pageid), 0x02 (cmd) GET wires: 0x03 (pageid), 0x04 (cmd) Data in: BlockPipeIn 0x80 Data out: BlockPipeOut 0xA0
Command queue (command FIFO)
Host says: “PUT page 123” or “GET page 123”. FPGA stores that request in command FIFO.
Input data queue (PUT data FIFO)
For PUT, the host also sends 4KB of data. FPGA stores that data in the input FIFO.
Output data queue (GET data FIFO)
For GET, FPGA reads 4KB from DDR. FPGA stores read data in output FIFO for the host to fetch.
DDR worker (state machine + MIG)
Takes one command from command FIFO. Executes it on DDR. Uses input/output FIFO depending on PUT/GET.
PUT (save page to FPGA DDR)
Host sends command: PUT page_id. Command goes into the command FIFO. Host sends 4KB page bytes -> input FIFO. DDR worker pops the PUT command from command FIFO. The DDR worker pops data from the input FIFO and writes it to DDR. Done.
GET (load page from FPGA DDR)
Host sends command: GET page_id. Command goes into the command FIFO. DDR worker pops GET command. DDR worker reads 4KB from DDR and pushes into output FIFO. Host reads 4KB from output FIFO. Done.
Why FIFOs are needed ?
The Host USB side and DDR side run at different speeds/clocks. FIFO is a buffer, so one side can wait without breaking the transfer.
MIG = Memory Interface Generator
It is an Xilinx IP block that implements the DDR3 controller. DDR3 DRAM is extremely complicated to talk to directly
The DDR worker is our logic.
It sits above MIG and decides:
- What page to read
- What page to write
- When to issue the operation
- Which FIFO to use
The DDR worker is our page engine that understands PUT and GET commands, while MIG is the Xilinx DDR controller that actually talks to the DRAM chips.
The Workflow of the Whole System
- Application allocates memory
- farmem_alloc decides:
- below threshold -> normal libc allocation
- above threshold -> place object in managed arena
- The arena is registered with userfaultfd
- First touch to a missing page causes a UFFD page-fault event
- Fault handler checks page state:
- IN_FPGA -> GET page from FPGA
- ABSENT -> zero-fill page
- track states like ABSENT / IN_FPGA / RESIDENT / LOADING
- Page is installed into host memory with UFFDIO_COPY or UFFDIO_ZEROPAGE
- If write-protect mode is enabled, later writes generate WP faults and mark pages dirty
- FIFO-based resident tracking pushes the page into the resident queue
- If resident memory exceeds the limit/high-watermark, the evictor chooses a victim:
- if dirty or not yet backed -> PUT page to FPGA
- then MADV_DONTNEED
- state becomes IN_FPGA or ABSENT
- On later access, the page can refault and GET again.
Evaluation
Test setup:
Main farmem settings used in most experiments:
- arena = 512MB
- resident cap = 16MB
- reserve = 32 pages
- prefetch = 0
- threshold = 768B
Measure:
- throughput (ops/sec or runtime)
- tail latency (p99)
- paging activity (faults_get, evictions, puts)
- managed DRAM residency
Benchmarks
- Redis + memtier: skewed KV/cache workload
- Memcached + memtier: second cache/KV workload
- TorchRec fused: optimized embedding/recommendation workload
- GAPBS BFS: irregular graph traversal workload
Sweeps performed
- Locality: random vs Zipf
- Dataset/model size: small to over Dram cap
- Near-memory cap: 16MB, 32MB, 64MB
1) Redis + Memtire
Fixed:
near-memory cap = 16MB, dataset = 64MB, ratio = 1:10 (mostly reads), and changed only the access pattern/locality
So the question was: If the dataset is bigger than the 16MB cap, does far-memory still work when accesses become more skewed?
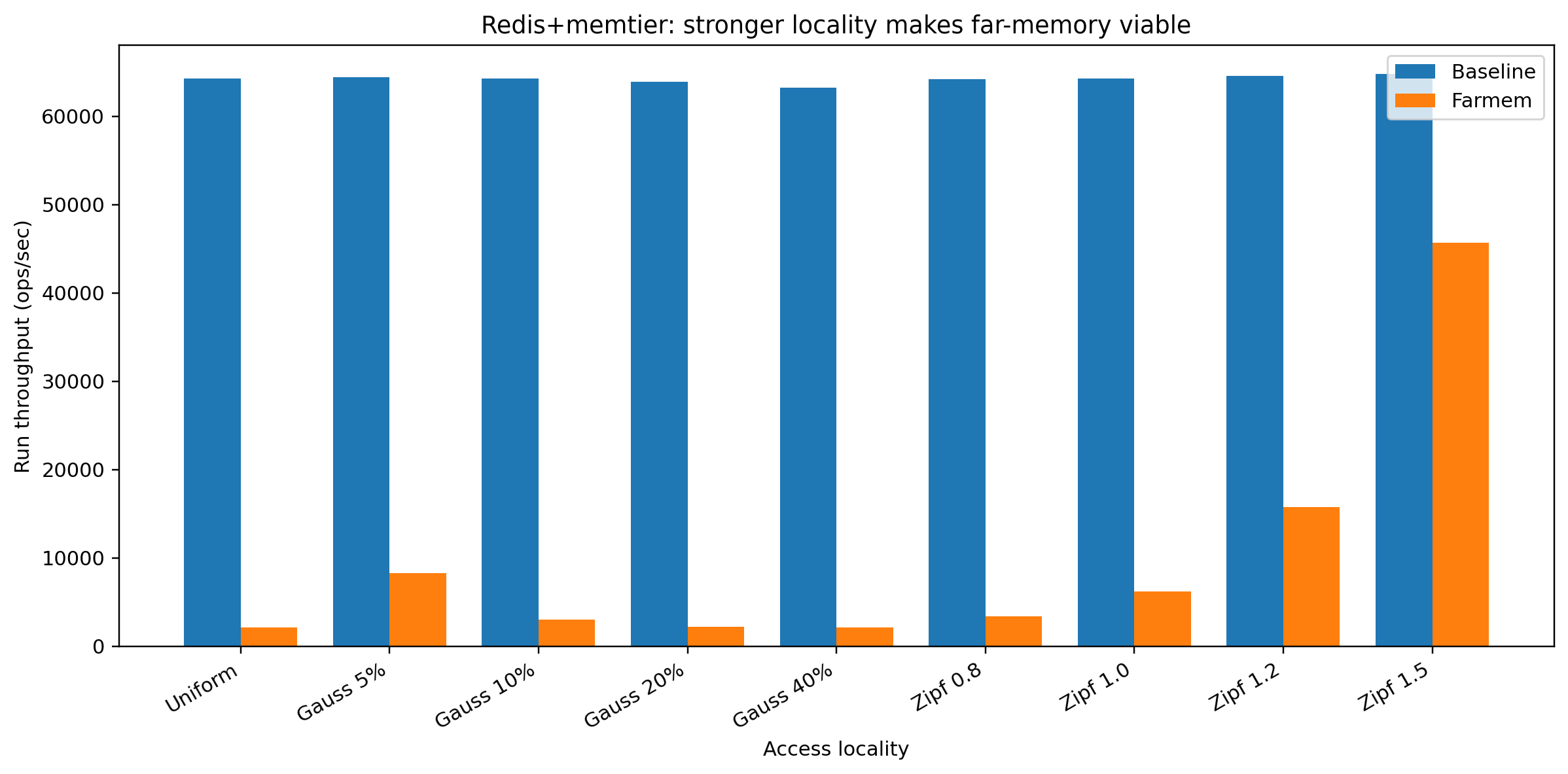
Under random access, Redis performs very poorly with far memory because the hot working set does not fit in the 16MB near-memory cap.
baseline = 64,277 ops/sfarmem = 2,154 ops/s delta = −96.65%
As the workload becomes more skewed, the same small set of hot keys is accessed again and again. That lets our system:
- keep hot pages in near memory
- leave cold pages in FPGA far memory
For Zipf:
- Zipf 0.8: farmem = 3,399 ops/s, delta −94.71%
- Zipf 1.0: farmem = 6,211 ops/s, delta −90.33%
- Zipf 1.2: farmem = 15,768 ops/s, delta −75.57%
- Zipf 1.5: farmem = 45,669 ops/s, delta −29.53%
At the same time, p99 improves from 7.359 ms in uniform random
To 1.439 ms at Zipf 1.5
So a stronger skew makes far memory much more practical.
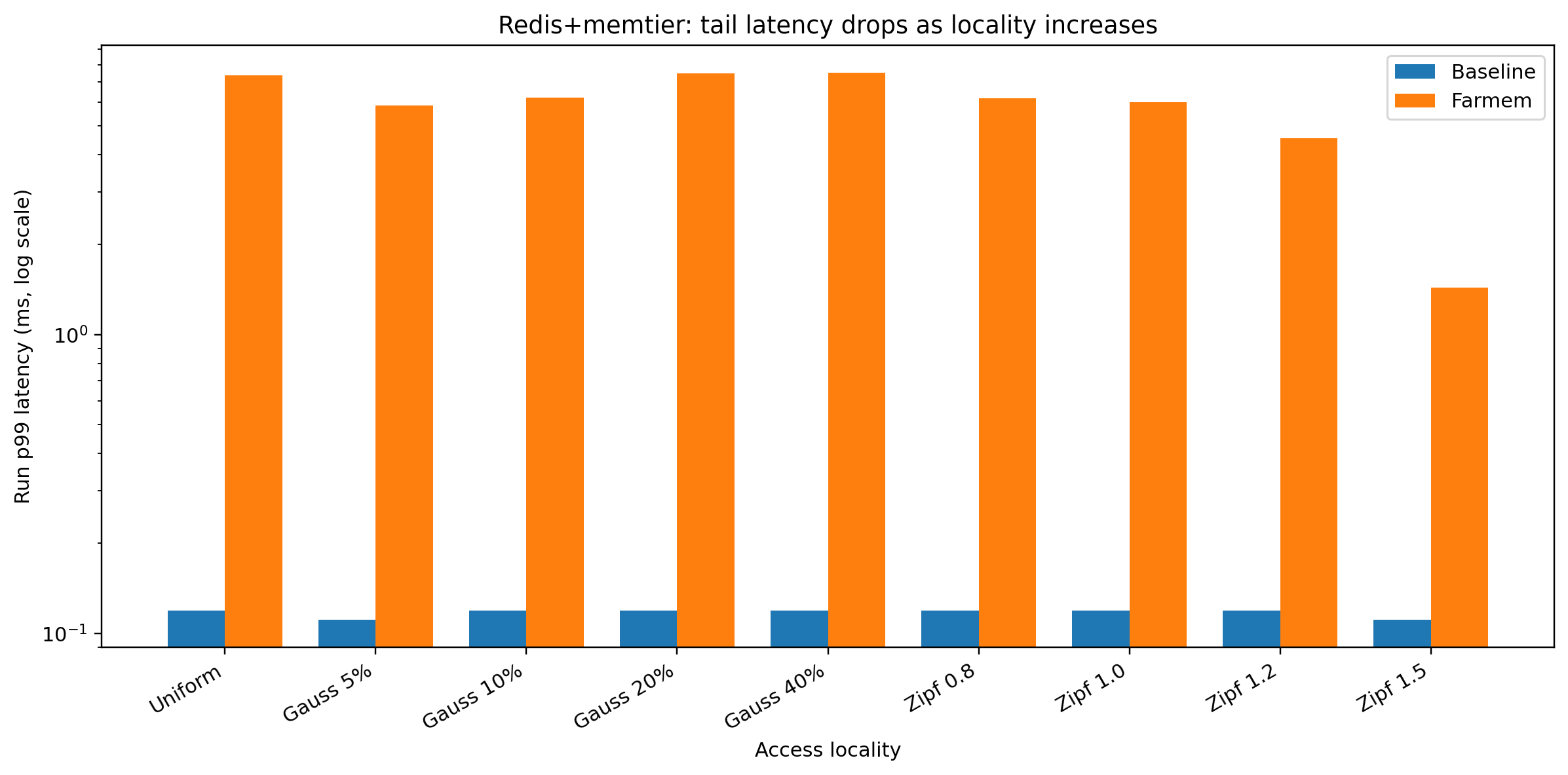
This graph shows the tail-latency story. Under random access, many requests trigger paging, and p99 becomes very large. Under strong skew, paging is much less frequent, so p99 drops significantly.
Dataset scaling under strong skew is also good.
We also did the Zipf 1.5 dataset scale test at the same 16MB cap:
- 64MB dataset: farmem delta −29.53%
- 128MB dataset: farmem delta −34.86%
- 256MB dataset: farmem delta −37.27%
- p99 only rises slightly: 1.439 ms → 1.479 ms → 1.511 ms
What that means - Even as the total dataset grows from 64MB to 256MB, farmem stays reasonably usable under strong skew. Therefore, our system is:
Good fit: cache / KV workloads where a small number of hot keys dominate requests.
Bad fit: random access across a dataset larger than the near-memory cap
2) TorchRec fused - Recommender System
Recommendation models do things like: predict which ad a user will click, which product a user might buy, which video/song/article a user may like
What is an embedding table? Think of it like a very big lookup table. Example: user ID 15 -> row 15, item ID 842 -> row 842, category ID 7 -> row 7. The fused path is the optimized implementation, so it is the one worth discussing as a realistic system result.
So what did this benchmark test - Can our far-memory system support a large embedding workload while keeping only a small amount of that embedding memory resident in DRAM?
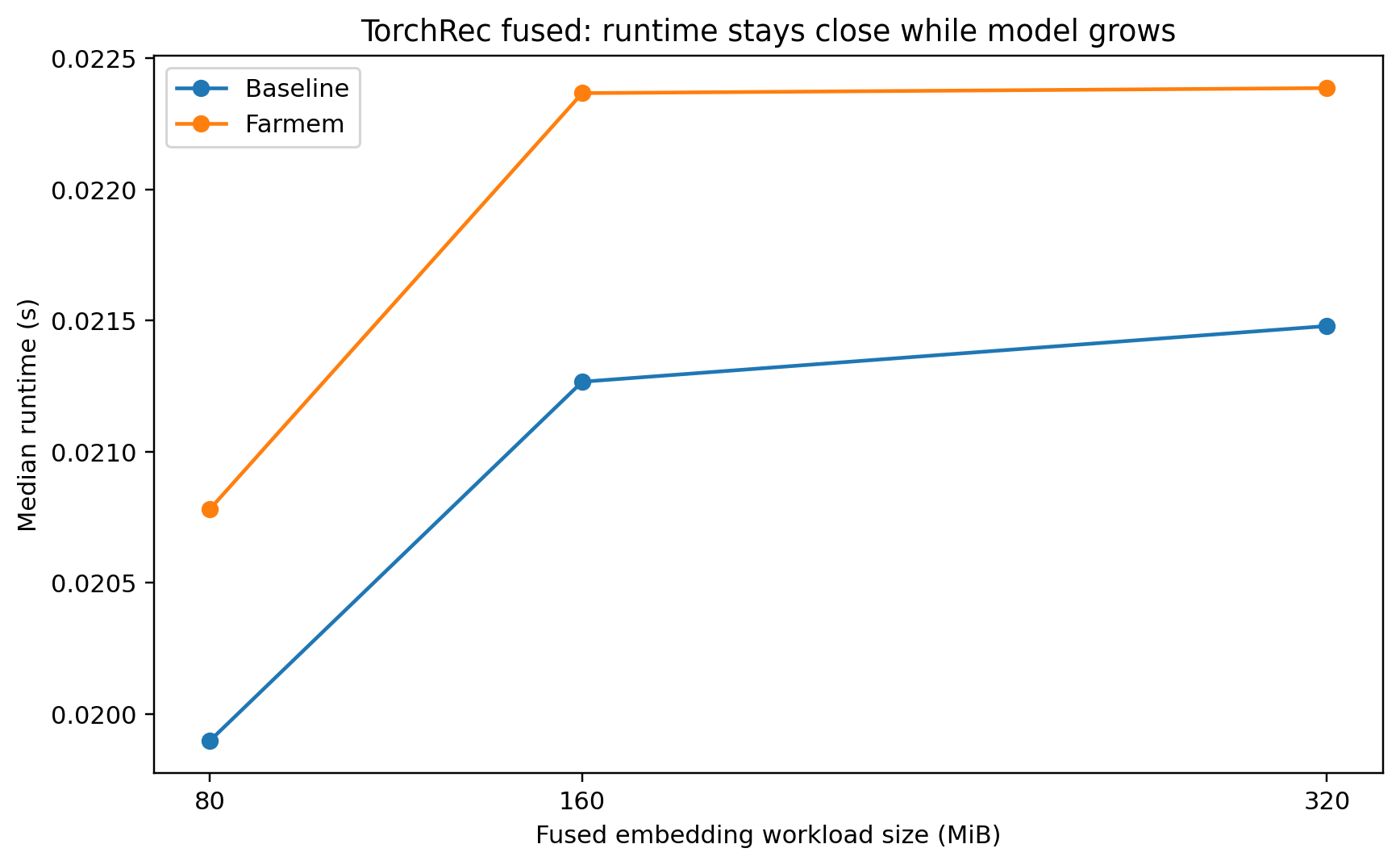
If we see the 80MB fused embedding workload:
Baseline resident embedding memory: about 80.039 MiB.Farmem resident embedding memory: about 15.875 MiB. So farmem kept only about 1/5 of the embedding region resident (Scale test below)
At the same time, the no-replay fused run showed only about: +8.736% slowdown compared to baseline
Scale Test
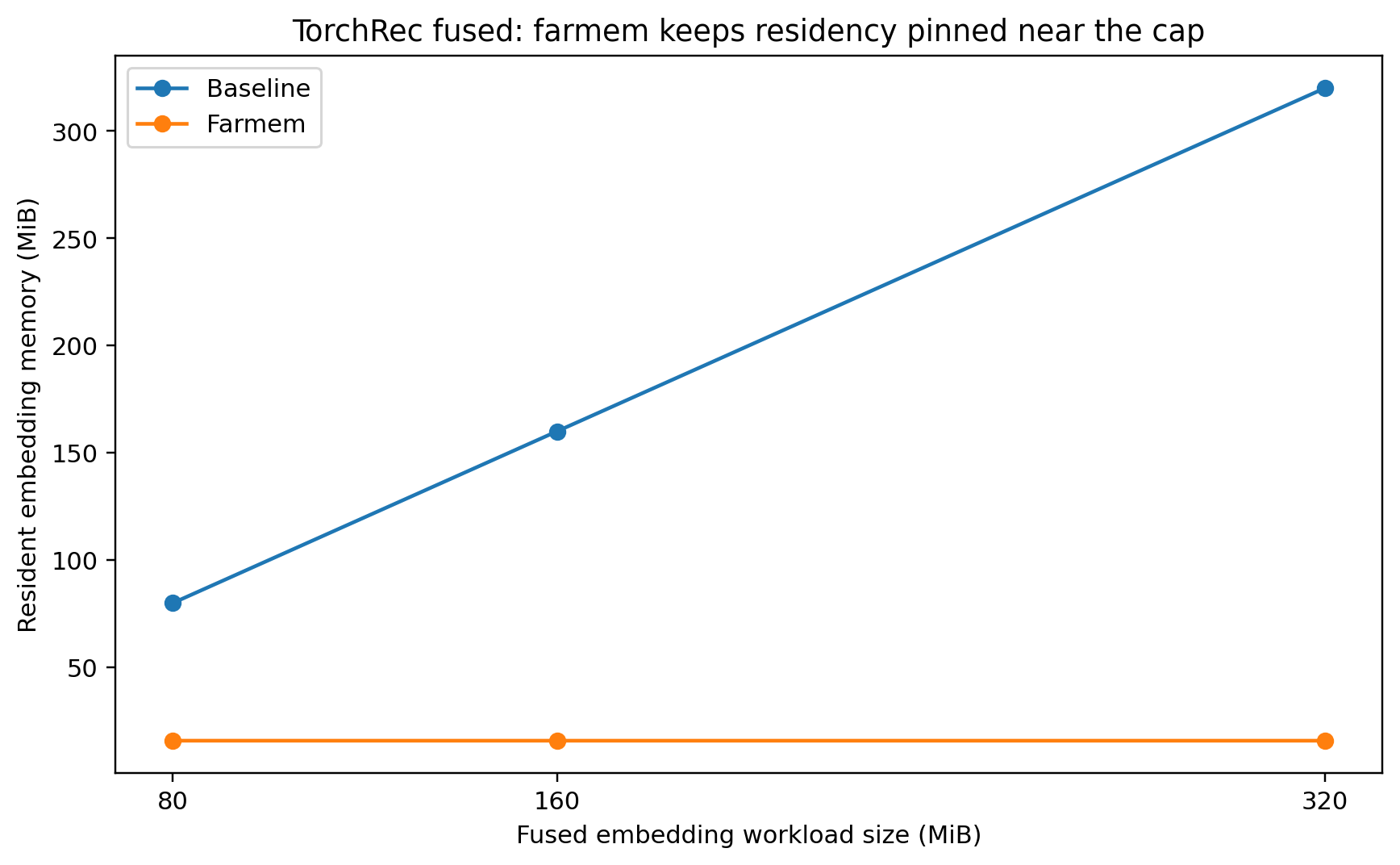
In the scale test:
80MB -> 160MB -> 320MB
farmem slowdown stayed only about 4-8%, farmem resident memory stayed near 15.87MB, and baseline resident memory grew with workload size
This means - For optimized fused embedding workloads, our far-memory system can reduce managed DRAM residency a lot while keeping runtime close to baseline.
3) GAPBS Benchmark
GAPBS is a graph benchmark suite. BFS is a good benchmark for far memory because it is a hard, irregular workload
Unlike Redis Zipf or fused embeddings:
- BFS often touches memory in a scattered way
- Access is less predictable
- locality is weaker
Graph scale sweep Ran BFS with:
g14,g15, g16 while keeping the farmem cap fixed at: 16MB
This test shows what happens as the graph gets bigger.
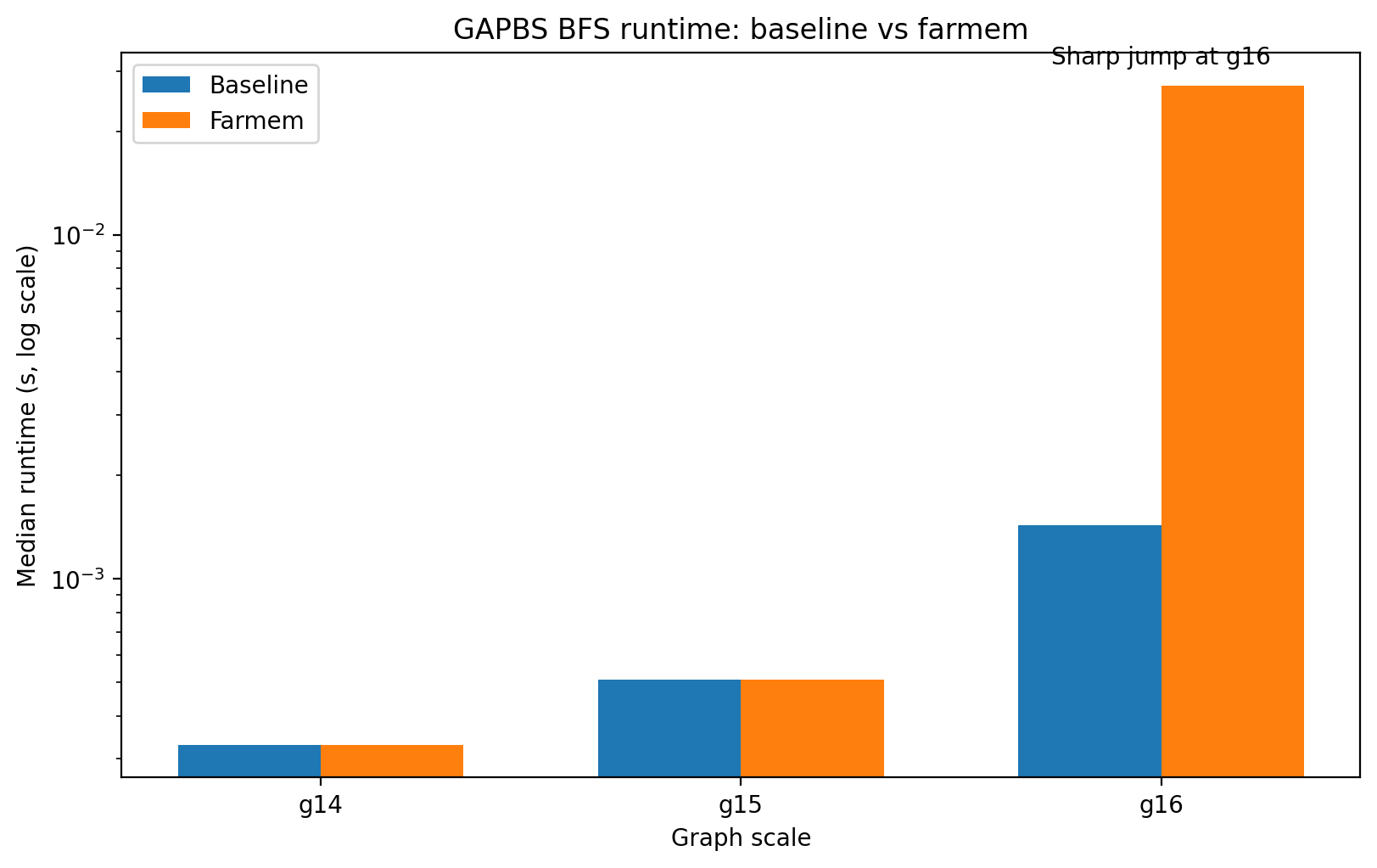
For g14 and g15, the results were basically identical between baseline and farmem:
- g14: baseline 0.000330s, farmem 0.000330s
- g15: baseline 0.000510s, farmem 0.000510s
- evictions = 0
Which means - At these graph sizes, the active graph data still fits in the Dram cap well enough that farmem does not really have to page.
For g16
- baseline: 0.001430s, farmem: 0.027170s
- slowdown: about 18×, faults_get = 4412, evictions = 6670, puts = 4681
Which means - Now the active BFS footprint is too large for the 16MB cap.
Once the graph working set exceeds the near-memory cap, BFS becomes extremely slow because it triggers thousands of page fetches and evictions.
Cap sweep at fixed graph size
fixed:
graph scale = g16 and changed the cap:16MB, 32MB, 64MB
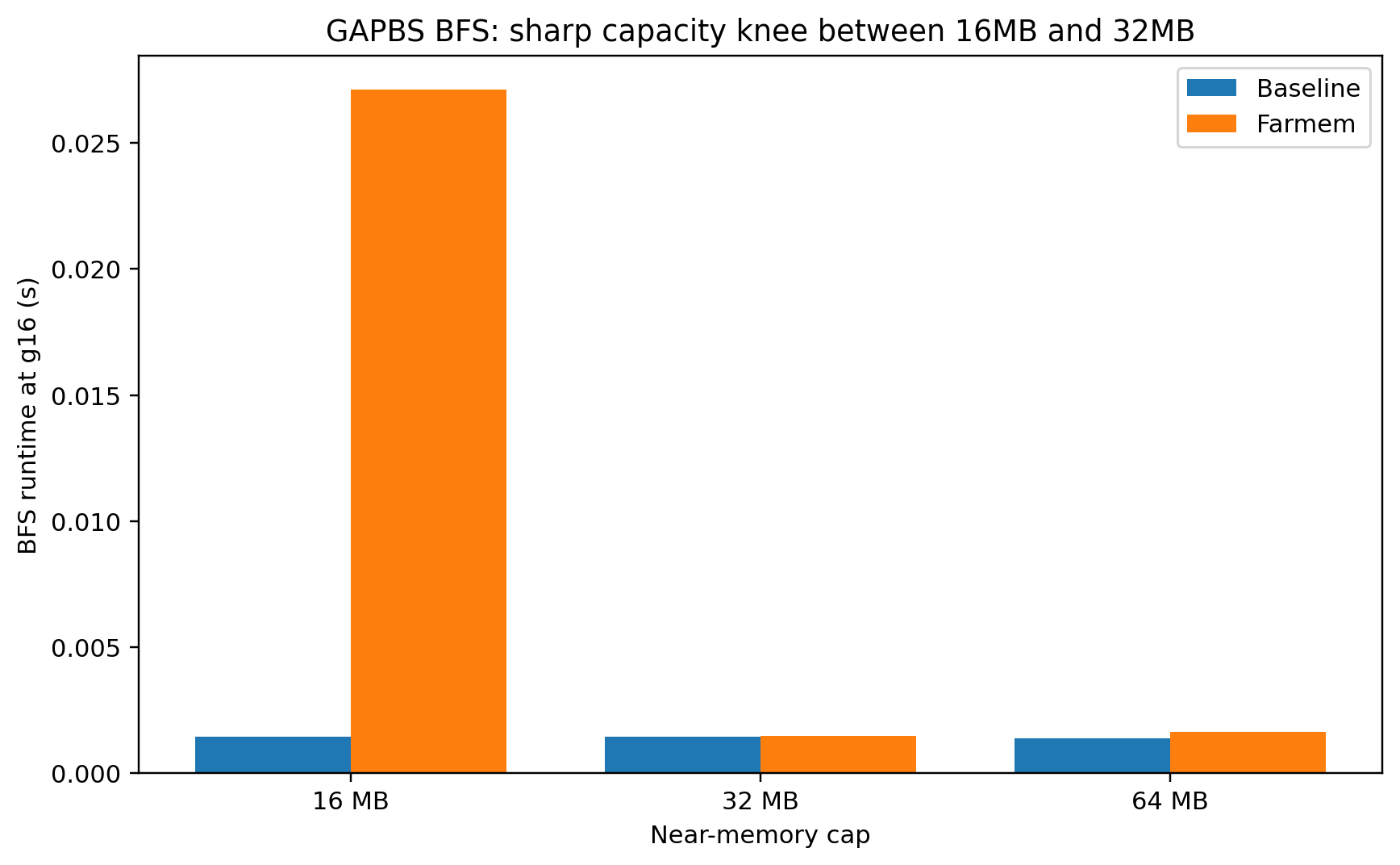
Once we double the cap from 16MB to 32MB and beyond, the active BFS footprint now fits, and paging disappears. This is the capacity knee.
BFS has a very sharp near-memory capacity threshold. Below the threshold: near baseline. Above the threshold: severe collapse
This tells our system is not a good fit for: irregular graph traversal workloads whose active working set exceeds near memory
Fine for: the same graph workload if the active footprint fits inside the cap
4) Memcached: secondary KV cache benchmark
Memcached is a very simple in-memory key-value cache workload.
For our test, we fixed:
near-memory cap = 16MB, value size = 1KB, then changed: dataset size using number of keys, access pattern using random vs Zipf
Unlike the Redis test, we did not try different values of Zipf, only the default.
So we asked if the dataset is slightly above the cap, moderately above it, or far above it, how does farmem behave for cache workloads?
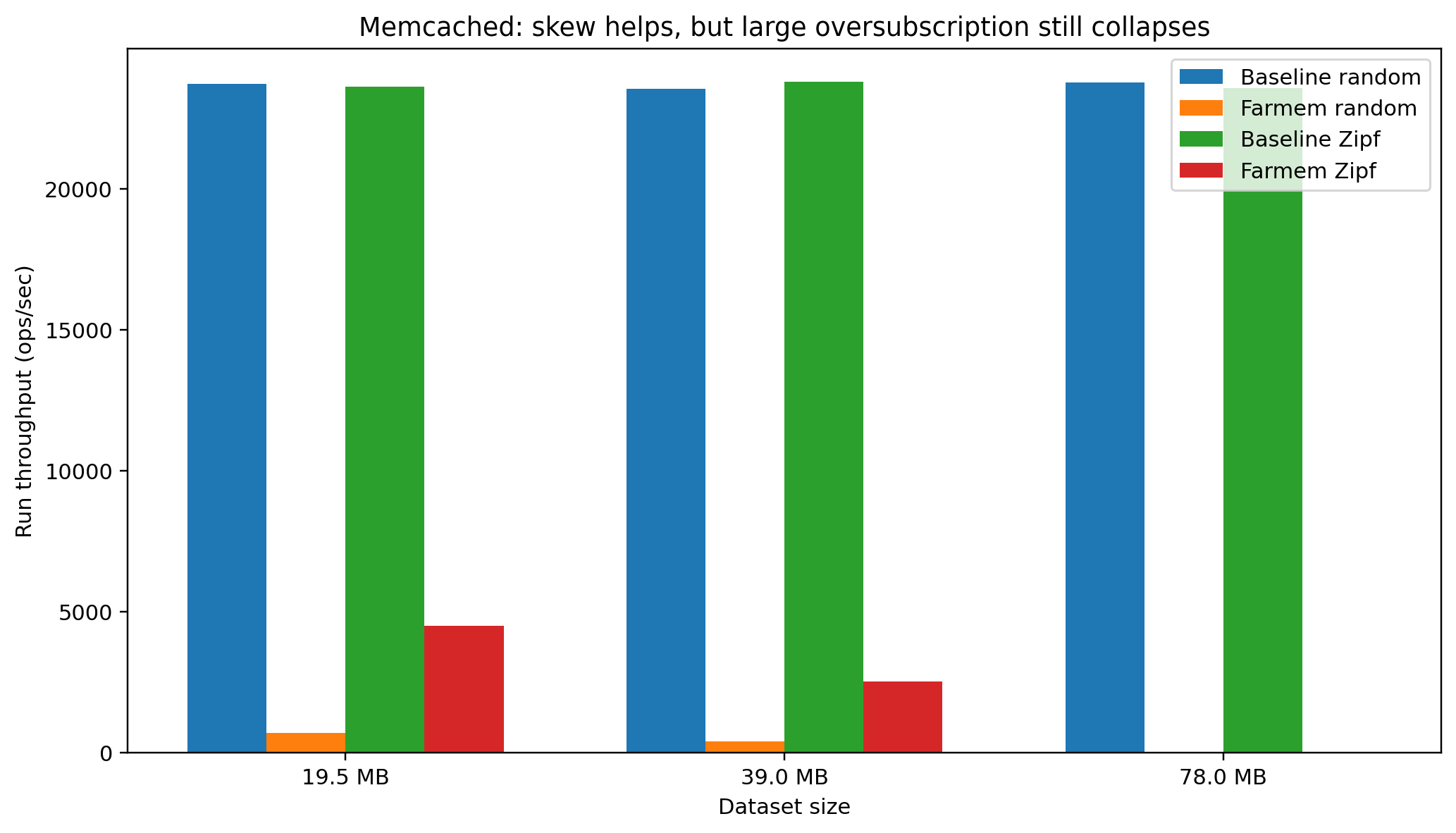
Zipf results -
Zipf, 20k keys (19.5MB)
- baseline: 23,615 ops/s
- farmem: 4,504 ops/s
- delta: −80.9%
Zipf, 40k keys (39MB)
- baseline: 23,787 ops/s
- farmem: 2,532 ops/s
- delta: −89.4%
Zipf, 80k keys (78MB)
- baseline: 23,564 ops/s
- farmem: 24.9 ops/s
- delta: −99.9%
Zipf is much better than random at the smaller sizes
But as the dataset gets much larger than the cap, even Zipf collapses
Zipf access improves Memcached performance because hot keys are reused, but when oversubscription becomes too large, even skew is not enough to save it. So not all cache workloads are good for far memory; they need enough skew/locality.
Challenges (The Hardest Parts To Get Right)
Hardware
- Designing and debugging the host–FPGA communication protocol
- Learning and integrating the Opal Kelly FrontPanel SDK
- Correctly configuring Wire/BlockPipe endpoints
- Handling asynchronous host–FPGA timing differences
- Integrating and understanding the MIG DDR controller workflow
- Debugging data movement and synchronization across FIFOs
Host Runtime Engineering
- Designing the page eviction policy and DRAM working-set management
- Implementing userfaultfd-based paging
- Managing page states and metadata tracking
- Handling concurrency between the fault handler and eviction threads
System Integration
- Building and validating the transport layer (PUT/GET correctness)
- Choosing representative benchmarks (Redis, Memcached, TorchRec, GAPBS)
- Designing the testing environment and parameter configurations
- Ensuring correctness under different workloads and scales
What Was Surprising
Everything, and the fact that we actually made this work in less than 6 weeks
Future Extensions
Phase 3’s basic implementation of a hotness table tracker was completed, but full system integration was not included due to time constraints. For future extensions, we will look at incorporating the hotness table with the rest of the project and rerunning the same tests as before.
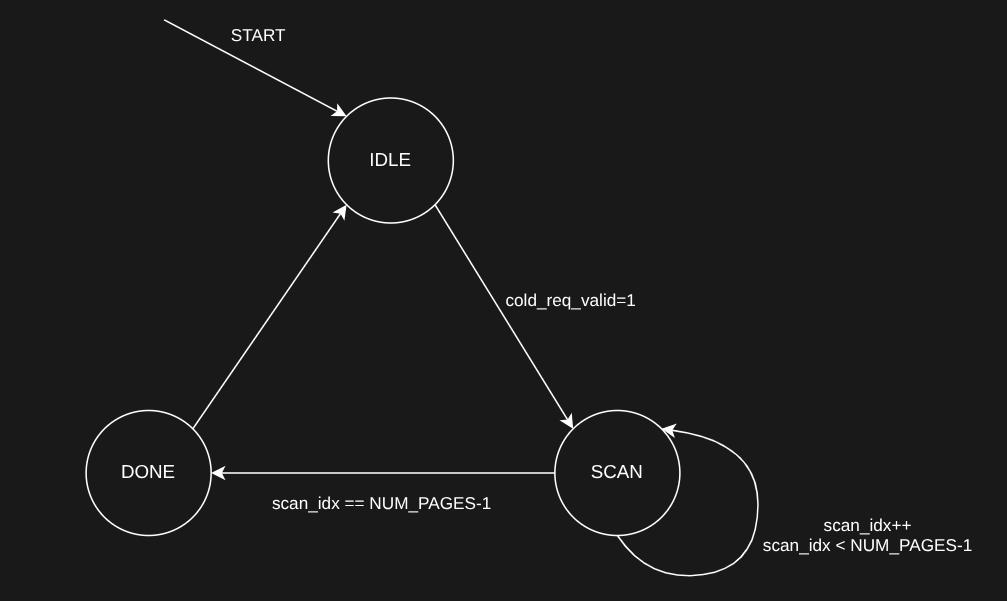
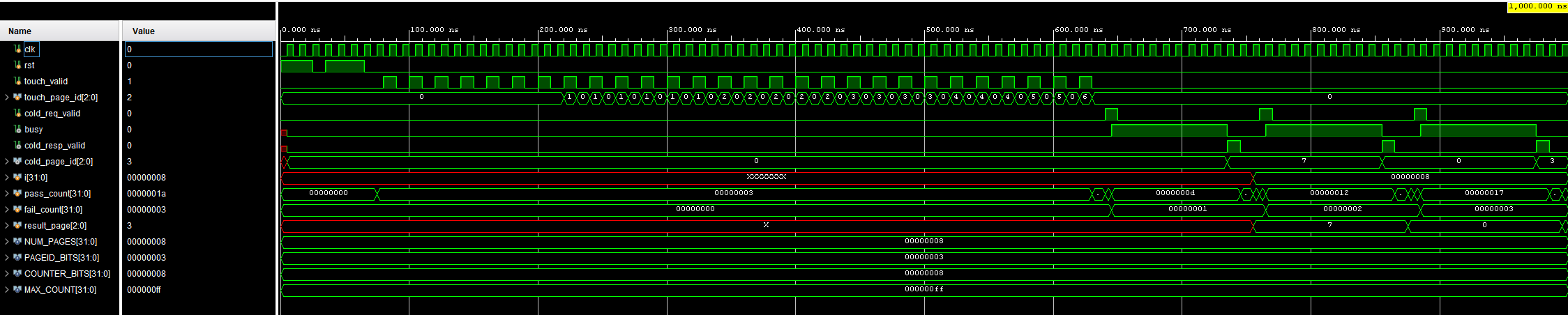
Vivado testbench simulations showed the initial hotness table is working as intended.
Conclusion
This project shows that FPGA-backed far memory is useful only for workloads with a small hot working set and a much larger cold data region. In our results, Redis under strong Zipf skew and optimized TorchRec fused embeddings remained close to baseline while using much less managed DRAM, showing that far memory can provide effective capacity extension. In contrast, random access Memcached and irregular GAPBS BFS degraded sharply once the active working set exceeded the near-memory cap, showing that far memory is a poor fit for weak locality workloads. Overall, the main value of our system is not speedup over DRAM, but maintaining acceptable performance while reducing near memory residency for locality-friendly workloads.
Division of Responsibilities
Phase 1 Hardware design and communication/protocols - Suvrojyoti Paul
Phase 2 Host side design and policies - Suvrojyoti Paul, William Davis, Adam Bobich
Phase 3 Hardware of hotness tracker - Carlos Alvarado Lopez, Allen Lee
Repo
https://github.com/SuvrojyotiPaul/Fga-Based-Far-tier-Memory-System